
Recommender Systems: From Filter Bubble to Serendipity
Recommender systems power a lot of our day to day interactions with the content we see on the internet. With over 2.5 quintillion bytes of data created each day, the last two years alone make up 90% of the data in the world [1]. We produce content at a level that is simply impossible to consume in one lifetime, and that makes recommender systems inevitable. However, as Uncle Ben said, with great power comes great responsibility. Here I talk about some of the practical and ethical problems that recommender systems raise, and how we can go about solving them.
What do recommender systems do?
Recommender systems is at the forefront of the ways in which content-serving websites like Facebook, Amazon, Spotify, etc. interact with its users. It is said that 35% of Amazon.com’s revenue is generated by its recommendation engine[2]. Given this climate, it is paramount that websites aim to serve the best personalized content possible.
What the user wants
As a huge recommender systems geek, I am always pleasantly surprised whenever I see a good recommender system. I am interested in consuming a lot of content (and I do), but there are not enough hours in the day for me to personally go through everything available for me to consume. I want recommender systems that can understand what I really want to read/listen to/consume at that exact moment, perhaps even when I don’t know what I want.

It used to be that when the content available to you (either through the results of a search, or some other way of wading through the available content like a top 100 list), you had to narrow down your results using some sort of filtering. This filtering often took the form of longer, more explicit search terms, date restrictions, including and excluding certain tags, and many others.
Those days are now over.
As a user, I expect that I will have assistance in sorting through all the content produced on a website. I believe that when I search for std::list on Google, I find the relevant links. Contrary to a lot of people, I also like personalized ads. If these personalized ads actually make me realize that I am missing some crucial item in my life, I would gladly make the purchase. However, that also does not mean that I like seeing the same mahogany chair following me around 12 different websites just because I looked at a chair once back in 2003.
Does that sound spoiled? Maybe. But that is the landscape we live in right now. It is the only way we can remain efficient when the generated content is growing exponentially.
What the company wants
As mentioned above, recommender systems generate a lot of the revenue for many of the major brands in the world. For some, it is the front and center way that a user interacts with the product (ex: Facebook’s news feed). For others, it might supplement the core functionality of the product through personalization (ex: Google’s search engine) or might be a way to keep a user engaged as long as possible (ex: YouTube’s up next feature).
No matter how you frame it, businesses are businesses, and they are driven by different goals than the consumers. Improving customer experience is paramount for all businesses, and for web-based businesses, this often results in trying to make the experience more personalized for each individual user, creating the need for a recommender system.
So far so good, right?
Let’s take a closer look to how an average website can use recommendations to improve user experience:
- Company X realizes that they generate more content than a single person can interact with. Moreover, their competitors are using personalization so that their users can have easier access to relevant content.
- Company X tries their hand on personalizing their search results. They choose a tried-and-true method like matrix factorization, and leverage their historical data to train the model.
- The trial is a resounding success! The A/B tests show that the revenue has increased by 4%, and their monthly active users has increased by 13%!
- Company X invests more resources into their personalizations. Multiple Data Scientists are working on implementing better Machine Learning models that perform better and better on their historical data, as they acquire more and more data.
- They automate the validation such that they can set specific revenue/user/conversion rate/other KPI targets in any combination and try to optimize it using A/B/n testing, which automatically incorporates any new Machine Learning model, constantly improving the quality of recommendations while achieving better and better targets.

This is indeed the dream scenario. You have the historical data points that can provide some training targets (loss functions) and testing targets for your Machine Learning models, and even though you know they are not necessarily a good indicator for the real-world value of a recommender system, you have A/B tests to optimize for the real-world results. Everything here can be quantitatively analyzed.
Well, expect for the “quality” of recommendations. And speaking of which, how do you even define the quality of a recommendation?
What should recommender systems do?
As mentioned before, there are a couple of practical and ethical issues with this approach.
In the context of a behemoth like Google, a recommender system has the ability to affect the very fabric of our society, and unfortunately, we are yet to understand the full implications of how it affects the society. It is obvious that Google facilitates a lot of the information flow on the internet, and getting cut off from Google is therefore a huge deal. But when it comes to quantifying the effects of this flow of information, we are stumped.
That does not mean we cannot reason about how recommendations should look like, and talk about some important concepts for recommendations in general. Keep in mind though, all of these concepts are product dependent: you will have to choose whether that is relevant to you or your customers.
Access to relevant content
This comes as a no-brainer, but for completeness’ sake, this is an area that should not be ignored. If you have a recommender system, you want to make sure that it recommends content that is relevant for the user. If I read exclusively fantasy books, then the recommendations I am getting should be largely biased towards fantasy titles. That does not mean I won’t enjoy the occasional action or non-fiction recommendation, but I should not be seeing my recommendations dominated by such genres.

One culprit of such recommendations is the Collaborative Filtering approach to recommendations. Continuing with the book example, if there’s a predominant second genre among the rest of the fantasy readers, collaborative filtering will bubble up that genre to you, even if you do not want to consume it. Worse yet, if the recommender system is relying on explicit ratings (1-5), you usually have to consume and rate it bad in order to get rid of such recommendations.
One way to combat this is using a hybrid model that also leverages content-based recommendations, which is the solution we went with for Books2Rec. That way, you can balance the collaborative filtering with content similarity.
Balance the Diminishing Returns
Diminishing returns are a well-understood concept in econometrics and psychology. The concept is pretty simple: the more you have of something, the less you want it.
To give a personal example, I really like listening to a single song until I’m sick of them, or binging Friends until I simply can’t handle another fight between Ross and Rachel.

Of course, this seemingly runs contrary to the previous notion of getting relevant recommendations; that will hit a point of diminishing returns. The key aspect here is timing: you are likely to get sick of seeing the same type of recommendations (based on your historical data) during a single visit to a website, but when you come back a week later, you don’t want to start from somewhere far away from your historical data.
Recommender systems typically make the distinction between historical and contextual (session-based) recommendations. Historical recommenders make use of the full extent of your historical data to find the next thing you would want to watch, while contextual recommenders take a look at your current session (think of it like the last hour of your Spotify/YouTube session) and predict what would best fit to you right now.
Of course, these two systems are not cut and dried, there is most certainly an overlap, and the right recommender system is somewhere in between. Contextual models work best when the opportunity cost is low, and where rapid consumption is viable. Diminishing returns is also more of an issue with the contextual models.
Long Term Returns
Another problem with recommenders in general is the best-recommendation-first policy. Think of a recommender system that can fully capture what you value in a video, and recommend you the 5 videos that will be the best 5 videos you will ever watch.
What happens when you finish consuming the best possible content?
The recommender system will keep recommending you the same type of content, but because you’ve already consumed the best, each and every one of them will be worse than the previous.
By doing its job too well, a recommender system can reduce your future enjoyment.
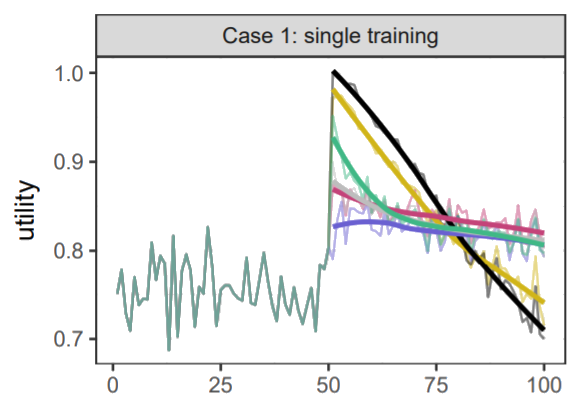
Now, of course, a lot of content is produced every day, and there’s a very good chance that the best possible content for you is not produced yet. But the fact remains that the top N content for you (or the top N content for the general public) is a hard list to get into, and you might get a better overall enjoyment by spacing the best content.
Another way of thinking about is that we should aim to maximize the long term reward of our recommendations. Put that way, it is easy to draw an analogy to Reinforcement Learning, and to algorithms like MDP (Markov Decision Process) and Bandits, especially in terms of exploration vs exploitation. And sure enough, we can see a lot of interest in Reinforcement Learning for recommender systems in the recent years.
Filter Bubble
Another result of the previous scenario is a phenomenon that is called the filter bubble. Coined by Eli Pariser and made famous by his book of the same name, filter bubble is the idea that you become trapped inside a bubble wherein only the information that a personalization algorithm (a filter) thinks you would like gets passed in. As you give the system more and more data, your bubble becomes smaller and smaller, a niche within a niche. You get trapped in a positive feedback loop with no escape.

Not only does this limit your options by not displaying content you might’ve liked, over time it homogenizes your interests, which results in you losing interest in different types of content, which again decreases your options. Worse yet, because of diminishing returns, you start to enjoy the content recommended to you less and less.
All is not lost, though. As designers of recommender systems, even if we cannot reliably solve this problem, we can give the users a way out. It doesn’t have to be fancy - even an unbiased and de-personalized search system might give the users enough tools to reach content that is outside of their filter bubble. Even if you rely on implicit ratings, a user can over time shift the recommendations to somewhere more diverse.
Note: A related term that is more associated with politics is echo chamber, which has more to do with the interactions of people with like-minded people and getting more and more confident that their thoughts are the right ones. I will not be covering that.
Diversification
Diversification is a way in which we can fight the effects of the filter bubble and diminishing returns. Unfortunately, it is not a natural byproduct of recommender systems; instead, we have to work for it.
I have observed that users can be broadly categorized into two categories in terms of their taste diversity:
Social users are your typical users with some loosely-defined genre preferences, but are satiated with consuming the items in the top N lists. If a piece of content is popular and/or it has been shared by their friends, they also want to consume it. If you modeled their distribution of tastes as a Gaussian Mixture Model, they would have shallow peaks and a lot of overlap.
Power users care more about consuming content that they care most about. There are less of them when compared to the social users, but they still make up a sizeable portion. Some of these users start off with a pretty diverse set of interests. In terms of a Gaussian Mixture Model, they would have high peaks and a lot of dead zones in the middle.
It is in our best interest to keep and nurture these diverse set of interests. Some researchers model these tastes explicitly[3], while others try to learn them more organically. As will be explained later on, it might still be in your best interest to force some diversity in even for users with highly specific interests.
By optimizing for the average, you end up sacrificing the higher fidelity recommendations that your power users rely on.
The problem with diversity is that it is hard to measure exactly how diverse a set of recommendations is. In a recent episode of TWiML&AI, Pinterest Data Scientist Ahsan Ashraf talks about a set of guidelines you can use as a sanity check for any recommender system - diversity measure pair:
- Stability: As we give a recommender system items of the same topic/genre, does it converge to that topic, resulting in the recommender system “overfitting” to that topic? How fast does it converge? How diverse are those recommendations?
- Sensitivity: Suppose you have two topics A and B, and start with a 100 items of A. Do the recommendations cover the whole spectrum (from only a little bit of B to all B_s) as you add more and more items from _B? Is your diversity maximized at 50:50 ratio and minimized at 100:0 and 0:100?
- Sanity: Are completely random recommendations more diverse than the average recommendations for a user? Are topic-specific lists less diverse than the average recommendations for a user?
Serendipity
Taking one more step forward from diversity, we come to the concept of serendipity, which is finding something valuable or beneficial while not looking for it, a happy coincidence. It is finding something that simply blows you away.
I like dividing serendipity into two categories: immediate and eventual. Immediate serendipity happens, well, immediately. You’re walking along the streets, and you look up - without any specific reason - and see the Empire State building.

Eventual serendipity (which perhaps is a misnomer, but I have yet to find a better name for it) is when you look back at your life, and realize one random event led you on a journey that shaped part of who you are.
In order to realize the importance of serendipity, think of that random incident that led you to discover your favorite artist, or your best friend, or that moment when you realized this was all you had been looking for.
Wouldn’t it be great if we as the designers of a recommender system could facilitate this event?
Looking at it analytically, we can use a proxy for the actual serendipity (which is very hard to quantify) with looking at items that the probability of the user having heard of that item is low and the probability of user liking that item is high. The problem then becomes calculating these two probabilities, which we can approximate using any number of methods.
Of course, this proxy is not ideal, and there is ongoing research on trying to figure out a better way to formulate this problem. One thing that we know is that we need some sort of diversity or randomness in order to facilitate that.
Obviously, this lends itself to some problems easier than the others. It is much easier to be more experimental in song recommendations than book recommendations. This is due to what the economists call the “opportunity cost”. Each time you interact with something, you choose not to interact with the others. In music, if you fully listen to the song, you might lose 4 minutes of your time, and you even have the option to skip it. Thanks to music streaming services, you probably won’t pay anything extra to engage with that content.
However, a book is a longer term investment. It might take you a 100 pages to realize that book is not a good fit for you, and by that time you might’ve spend a couple of hours and $10 for the book. Therefore, it is important to be (on average) more conservative doing book recommendations than music recommendations.
A case study in algorithmic confounding
A recent paper[4] from the researchers at Princeton University discusses the further effects of the feedback loop generated by a recommender system. More specifically, they look at the confounding that occurs when models attempt to capture user preferences without accounting for the fact that the choices the user was presented with was also generated by the model, weakening the causal impact of recommendations on user behavior.
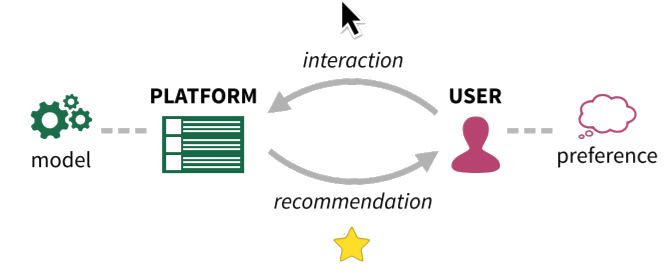
The major claims made in the paper are as follows:
- Not all algorithms benefit from retraining using confounded data (that is, data that has been generated as a result of the recommender system).
- Evaluating a model using confounded data are biased to move the data in a direction that fits the algorithm, creating a feedback loop that should not exist in the underlying data.
- The previous feedback loop works to homogenize both individual users and the whole set of users.
Without going into details, researchers model a realistic interaction sequence between users being recommended items, recommender system getting the results of those interactions, and updating its recommendations with that data and with new items that are introduced over time.
Researchers show that in terms of total utility, using confounded data works best with content-based models and social (trust-based) models, but do not have a significant advantage when using with Matrix Factorization models. Moreover, they show that evaluating the model using the confounded data generated by the same model leads to a greater improvement in scores compared to using the confounded data generated by a different model.
Evaluating your model with confounded data may therefore overstate the performance of your model.
This is also a worrying case for publicly available datasets used for research, that may themselves be confounded due to the recommender system that was used to create the data, and may therefore have hidden biases for certain types of models.
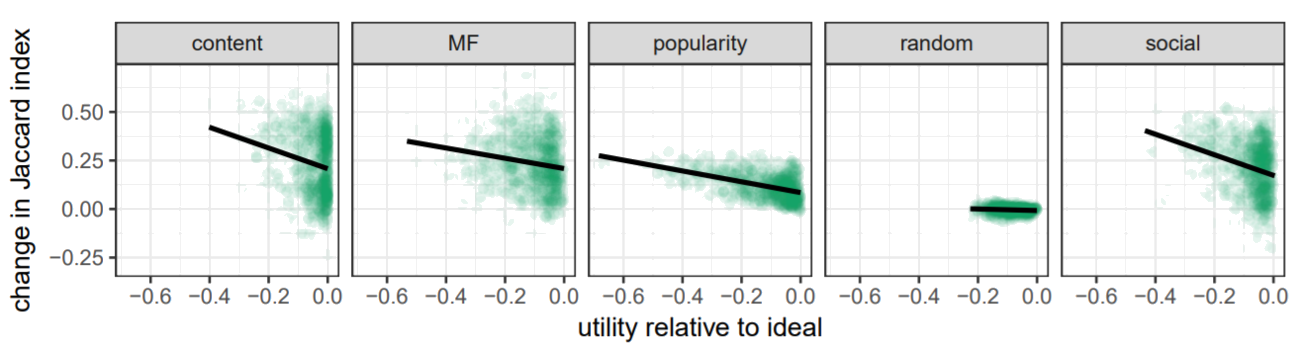
Researchers also measure the effect of homogenization on total utility, claiming that homogenization is good because it means the model is learning the underlying patterns, but can also block new items from being discovered that might’ve been beneficial for a user.
They find that homogenization (captured as the y-axis of the following plot) correlates negatively with total utility (x-axis), for all 4 methods barring the random model, which by definition does not rely on any model.
{kind=link}
It is therefore important that we try to keep our recommendations as diverse as possible, but at the same time, balance them with recommendations that make sense for the users. Again, we can draw an analogy to the explore/exploit problem with Reinforcement Learning methods. If we really want to achieve the best possible outcome, we need to find the right balance and work hard to keep it there.
Conclusion
Thanks to a growing interest from both the academia and the industry, we have today a lot of tools to make recommendations, and a better understanding of our tools. However, we are not yet at a point where we fully understand the consequences of our choices when building a recommender system. There is no free lunch, and there are always consequences to our choices, even if we cannot immediately see them.
I hope this post leaves you with some general ideas on what sort of stuff you have to keep an eye out for if you want to give the users the best experience possible. As the designers of recommender systems, we have the power to influence what reaches a user, and what doesn’t. It is up to us to use that power wisely.